
Introduction
Most software engineers know about operating system (OS) level processes and threads. They are taught in all university OS courses. However, newer concepts promising higher throughput, less overhead, latency, and development efforts have emerged.
I was perplexed as I couldn’t find a succinct and systematic description and comparison. This is precisely the goal of this article – to summarise, exemplify and compare terms like green threads, fibres, goroutine, actors etc.
This article aims to give a general overview of these concepts and is not exhaustive. There is still some terminological ambiguity with respect to some terms. For this article, I have mostly followed the respective Wikipedia pages.
Concurrency vs. Parallelism
Let’s start by clarifying two important concepts – concurrency and parallelism. Until recently I considered them synonymous and there is still some ambiguity in the community about what they mean.
According to Rob Pike’s talk, concurrency is about composing independent processes (in the general meaning of the term process) to work together, while parallelism is about actually executing multiple processes simultaneously. Concurrency is about the design and structure of the application, while parallelism is about the actual execution.
Naturally, the terms are related. In order to achieve efficient utilisation of a multi-core system (i.e. good parallelism) you need scalable and flexible design with no bottlenecks (i.e. good concurrency).
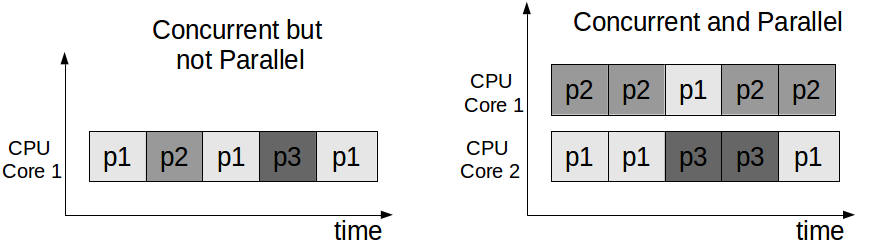
Let’s take a multi-threaded application as an example. The separation of the application into threads defines its concurrent model. The mapping of these threads on the available cores defines its level or parallelism. A concurrent system may run efficiently on a single processor, in which case it is not parallel.
We can have it vice versa as well. It is possible to have parallelism without concurrency. For example in SIMD architectures there are simultaneous/parallel computations, although only one instruction is run at a time.
Processes and Threads
If you know about OS processes and threads you may wish to skip this section.
A process is an instance of a program being executed. Each process has its own address space, which can not be accessed from other processes. Hence, processes are isolated from each other and can not directly access each others’ memory, which increases security and fault tolerance. Special inter-process communication techniques like sockets and pipelines can be used to communicate between processes. The OS preemtively schedules the processes’ access to CPU resources.
OS processes can be expensive to create, as each one has its own address space, program code, open file handles etc. Furthermore, the inter-process communication can be inefficient and cumbersome to program.
Enter threads (a.k.a. lightweight processes). A thread is a separate line of execution (i.e. a sequence of instructions) within a process. A process can have multiple threads, all of which share its address space, file handles etc. Starting a thread is cheaper, as fewer resources need to be allocated. The threads within a process are concurrent and can execute in parallel. Each thread maintains its own programming stack. Alike processes, the OS scheduler preemptively schedules all threads.
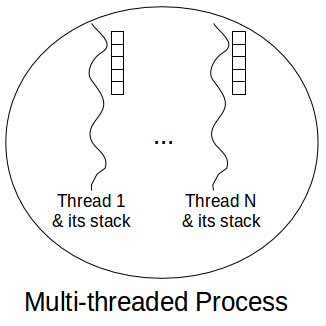
Since all threads within a process share the same address space, they can communicate much more easily. However, this makes multi-threaded programming notoriously difficult, as the access to shared variables must be carefully synchronised. Acquiring and releasing locks can significantly slow down an application as threads can be blocked for long time periods. Furthermore, blocking leads to context switching, which is expensive.
Another problem is that each thread has its own stack (typically ~2MB). This limits the number of threads you can have in a system to at most tens of thousands of threads for machines with large RAM. In a web server running a separate thread per client, this will limit the number of clients you can serve, although most of the threads may be idle (e.g. waiting on I/O). Thread pools and queues can be used to resolve the issue and to avoid excessive thread allocation. This may result in further contention, as the access to the pool itself must be synchronised and the number of incoming requests may be greater than the pool size, which is still limited by the maximum number of threads in the system.
Green Threads
When Java was introduced 20 years ago it featured threads as a core concept and aimed to run on all platforms. At that point some platforms (e.g. old Solaris systems) did not have native support for threads and the JVM could not map its threads to OS threads. Hence, they had to emulate threads on top of such platforms. Such threads are called Green Threads.
Green threads run in user space, and are scheduled by a library or a virtual machine (VM). Thus, the OS kernel “sees” green threads as belonging to the same process and can not schedule them on multiple cores simuateneosly! Therefore, green threads are a concurrency concept, but not a parallel one.
Java has effectively abandoned green threads in favour of mapping to native OS threads.
Protothreads
Protothreads are defined as stackless threads. All protothreads share the same stack and context switching is done by “stack rewinding”. They are not preemptable, and only switch context when a blocking operation is invoked. As there is no stack, all local variables are not preserved upon a context switch! Protothreads are available only as a C library, and are used for low-memory embedded devices. Documentation is not too much, except for some academic papers and a presentation. As they run on a single stack, I assume protothreads are concurrent but not truly parallel. Protothreads seem to be a programming abstraction for event driven programming, rather than a true parallelism enabler.
Fibers
Remember that threads are lightweight processes. Well, Fibers are lightweight threads :). Fibers implement user space co-operative multitasking, rather than kernel level pre-emptive one. Thus, a fiber can not be forcefully pre-empted by the OS kernel. A fiber must voluntarily yield its execution to allow another one to run. Fibers always start and stop/yield in a number of predefined places. This makes programming easier, as the programmers are guaranteed that their code will not be abruptly interrupted and its data structures accessed by another fiber. However, fibers must play nice and yield now and then to allow concurrency – this can not be delegated to the OS kernel.
Fibers do have their own stacks, but the fiber switching is done in user space by the execution environment, not the OS kernel generic scheduler. Yielding and resuming are respectively performed by saving and restoring the fiber’s execution context/stack also more generally known as continuation. Fibers have small stacks stored and managed in user space. These factors should significantly improve their performance compared to threads.
Fibers are a concurrency concept, but are not truly parallel. Typically, each fiber has a parent thread, just as each thread belongs to a process. Multiple fibers from the same thread can not run simultaneously. In other words, multiple execution paths can coexists in the form of fibers (i.e. concurrency) but they can not actually run at the same time (parallelism).
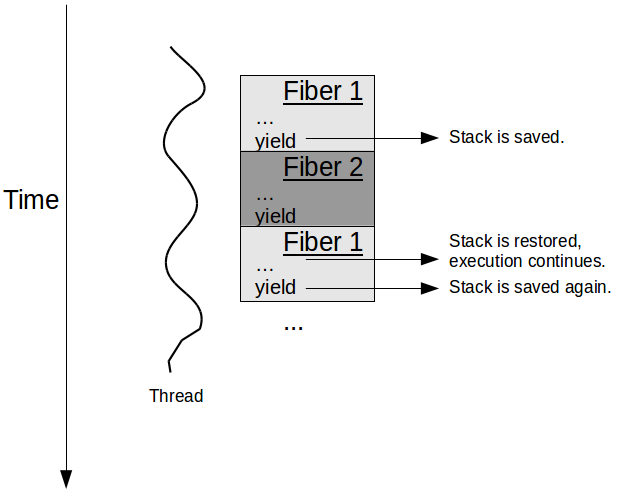
Fibers are usually short-lived tasks, unlike threads which are usually long lived. Hence, fibers can have smaller stacks. For instance, the Quasar library allows you to specify the stack size of new fibres. Hence, you can have much more fibers (i.e. millions) than threads (thousands).
There are a lot of articles online about the Quasar library, which supports fibers in Java. In my opinion Quasar fibers are not true fibers as per the above definition, and look more like goroutines, as they can achieve true parallelism and communicate via channels. They are more flexible, but not the same :).
So let’s give an example of fibers in Ruby. The following example defines a Fiber, which generates the Fibonacci numbers and is a modified version of the InfoQ example. After each number is generated, the fiber yields. Once it is resumed, the fiber reinstates its stack, generates another number and yields again.
1
2
3
4
5
6
7
8
9
require 'fiber'
fib = Fiber.new do
x, y = 0, 1
loop do
puts y
Fiber.yield
x,y = y,x+y
end
end
It is responsibility of the caller to start and resume the fibers. The following lines print the first 20 Fibonacci numbers.
1
20.times { fib.resume }
Computing Fibonacci is not the most impressive or useful example. Indeed, there is a much better use case. Let’s assume we have a wrapper of a native async library for downloading HTTP resources. The methods of this library can be provided with callbacks, which are executed once the async operation completes. In this scenario, the fiber can start an asynchronous HTTP operation and the yield. As a callback, we can provide an expression which resumes the fiber.
So we can have a fiber yield, while an external native library is doing extensive I/O, and then resume once this is done. Upon resuming the fiber can for example update the user interface (UI). This happens on the same thread! The alternative would be to start a separate thread for the I/O task, which blocks until it is complete and then concurrently modifies the UI.
For an example of how to use Fibers in Ruby in such situation, you can check out this article.
In fact this approach of wrapping a long running backround task in a fiber is so widesperead, that C# introduces a specialised Async/Await language structure for it.
As I mentioned, there is still some ambiguity in regard to many concurrency terms. For example, in Quasar fibers can run in parallel. GHC and Mercury can migrate fibers from one thread to another, and GHC can even preempt them. In this section, I’ve use the Wikipedia definition of Fiber, but other definitions exists as well.
Generators
As a step towards coroutines, we will discuss generators, also known as semicoroutines. You’re probably familiar with this concept if you’ve studied python or a functional language like Lisp.
Most programming languages have the concept of subroutines in the form of procedures, functions, or methods. When called, a typical subroutine completes at once and returns a single value. It does not hold any state between invocations.
From the client code, a generator looks like a normal subroutine – it can be invoked and will return a value. However, a generator yields (rather than return!) a value and preserves its state – i.e. the values of the local variables. Again, this is known as continuation. When this generator is called again, its state is restored and the execution continues from the point of the last yielding until a new yield is encountered. Subroutines can be thought of as generators which never yield.
The following example demonstrates a python 2 generator, which consequently produces numbers greater than n.
1
2
3
4
def countfrom(n):
while True:
yield n
n += 1
The following invocations demonstrate how generators work. Note that in python 2, the next method is used to call a generator.
1
2
3
4
5
6
# Create a generator
g = countfrom(5)
# Prints 5
print (g.next())
# Prints 6
print (g.next())
The first invocation of the generator reaches the yield statement, saves the local variable state (n=5) and yields its value. The second invocation restores the local variable (n=5), continues the execution after the yield statement and hence increases n to 6. When yield is reached again, the local variable state (n=6) is saved again and yielded to the caller.
Perhaps you can see a lot similarity between generators and fibers. Indeed, they are almost equivalent concepts. When a generator reaches a yield statement it saves its state and allows other code to execute. The same thing happens with a fiber, which saves its stack and lets another fiber run. When a generator is called, it restores its state and executes until a yield statement is encountered again. The same happens with a fiber, which once it is resumed runs uninterupted until it voluntarily yields.
Coroutines
Using a fiber library can be cumbersome, and thus some programming languages introduce coroutines. The two concepts are functionally equivalent. However, coroutines are implemented with specific syntax on the programming language level.
Coroutines are a generalisation of generators. When you are invoking a generator, you can not specify a parameter - i.e. in the previoous example we could not write g.next(7). Coroutines allow for this. When the coroutine is resumed, the specified value is provided to it in the form of a result of yield. The following example illustrates this:
1
2
3
4
def countfrom(n):
while True:
i = yield n
n += i
This code can be invoked as:
1
2
3
4
5
6
7
8
# Create the coroutine
g = countfrom(5)
# First call to the coroutine – Prints 5
print(g.next())
# Prints 7
print(g.send(2))
# Prints 10
print(g.send(3))
In Python 2 there are some syntactic specifics. When you call a coroutine for the first time,
you have to use next, just like with generators. Subsequent calls must use the send
method, providing the actual value. This is needed, because in the beginning the coroutine is not
halted/paused on a yield statement. The invocation of next intialises it to such a state.
Subsequent invocations of send actually illustrate the invocation of the coroutine.
Philosophically speaking, subroutines and coroutines are two different ways to structure a program. With subroutines, you’re dividing the program into subparts which execute to completion one after another. With coroutines, you divide your programs into collegial parts, whose lifecycles overlap, and which exchange messages by yielding to each other. If that was a bit too abstract, you may want to consult Berkley’s lectures for more details.
More details on Python generators and coroutines can be found in David Beazley’s presentation.
Remember that coroutines are not truly parallel. The same is true for generators and fibers. You can still avoid CPU blocking if you start some native asynchronous I/O and then yield, but you can not use multiple CPU cores simultaneously.
Goroutines
The Go programming language introduces the concept of Goroutines. They have been described as coroutines which can run in parallel. In terms of implementation, the Go runtime environment maintains an internal pool of native OS threads. Each goroutine is assigned to a thread from this pool which executes its logic. Once a goroutine blocks (e.g. for I/O) the runtime environment can use its thread for another goroutine. When a routine resumes, there is no guaranteer that it will be scheduled on the same thread.
Each goroutine’s logic is in fact defined in a function. The Go runtime acts as a mediator which schedules these functions on the underlying thread pool. In some special cases, a long running goroutine can be preemted and its thread given to another routine. Otherwise, the assignment of goroutines to threads is not preemptable. The overall goal is to minimise the time threads are blocked, and thus serve the application with fewer threads and context switches.
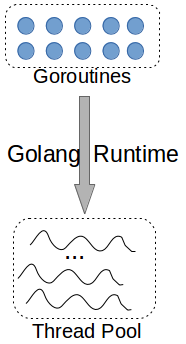
Goroutines communicate with each other via channels, similarly to processes communication. This alleviates the synchronisation issues of shared memory communication that threads have. This also bears some resemblance with how coroutines communicate by yielding values to each other.
Actors
Alike the Object Oriented Model, the Actor Model is a way to model computation. Originally developed in the 70s, the actor model is in fact rather simple. It introduces a single concept (the actor) which has a few basic properties.
So what is an Actor? According to the overview by Hewit et al. an actor has the following properties:
- Processing – an actor can do computation;
- Storage – an actor can maintain state, similar to a Java object;
- Communication – an actor can receive and send messages from and to other actors.
In the actor model, a system is represented as a set of actors which exchange messages. When an actor receives a message, it can do one or few of the following:
- Send messages to other actors;
- Create new actors;
- Change its state – this new state will be used for processing the future message.
A single actor is inherently non-concurrent (i.e. single threaded) and you need not worry about synchronising the access to its state. However, implementations of this model can run an actor’s logic in parallel if it is stateless/immutable – i.e. it does not use the last option of the above list. If an actor is stateful the implementation may choose to do some queuing. Either way, at a conceptual level you can think of actors as running one message at a time.
When an actor sends a message, it does not wait for confirmation or response (think UDP not TCP). Also, there are no guarantees about the order of message arrivals or delays. Hence, actors communicate in a completely asynchronous and distributed fashion. Moreover, actors are the atomic components in this model, share no state and are themselves non-concurrent thus removing the need for locks and synchronisation. Once you’ve built an actor model, it is inherently concurrent. You can deploy on multiple cores and even networked machines to achieve true parallelism.
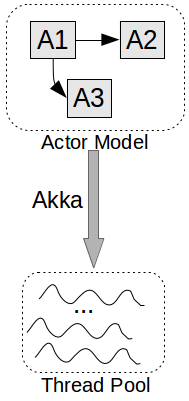
As a practical example of an Actor-based framework we can consider Akka - one of the most prominent implementations targeted at the JVM. In Akka actors are arranged in a hierarchy. Each actor is identified with its path from the root. Every parent actor is designated as a supervisor of its child actors. An actor can implement its own supervisor strategy, which gets executed when supervised actors fails. Typically, this is used for restarting or recreating failed actors.
Under the hood, Akka uses a thread pool. Based on the configuration and the message dispatchers (classes forwarding messages to actors), Akka schedules the actors on the available threads. Actors can also be replicated and put behind a Dispatcher which load balances the incoming messages among them. This can increase availability and responsiveness. Finally, actors can be transparently distributed on multiple machines or a cluster.
LMAX Disruptor
The LMAX Disruptor method is a way to implement producer-consumer systems more efficiently. It has been implemented as a Java library, but the approach can be applied in non-JVM environments. While actors, goroutines, and fibers propose efficient concurrent models “on top” of threads, the Disruptor library embraces the multi-threaded approach and tries to improve it. It does so by preallocating memory, avoiding excessive locks and utilising modern processors’ capabilities.
The library creators argue that locking data between threads is the main culprit for system latency. To a certain extent this has been mitigated by the Compare and Swap (CAS) capability of modern processors, allowing a piece of memory to be conditionally written in a single atomic instruction. This is how most java.util.concurrent atomic types work under the hood. Even with CAS, locking seems to be a performance bottleneck, as the CPU internally must lock its instructions pipeline.
Another major problem of the producer-consumer systems is the dynamic nature of queues, which are used to store data in a producer-consumer approach. Such queues can usually grow and shrink dynamically resulting in runtime memory allocation and garbage collection. This can significantly degrade performance. Furthermore, most queues are implemented as linked lists, and thus occupy non-adjacent memory addresses. This hinders the memory locality of CPU operations and can lead to many cache misses. Hence, the Disruptor library preallocates a static array of memory, which it uses throughout the execution.
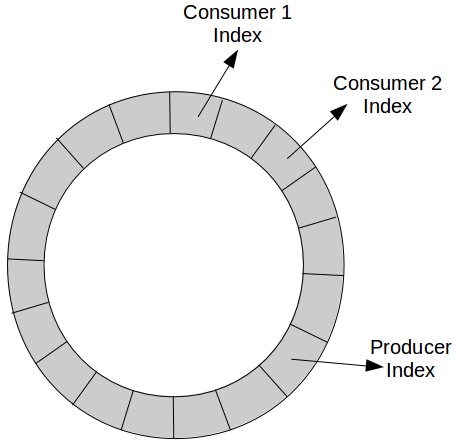
The data structure they use is a ring buffer, which is implemented as an array. The elements/objects of this array are preallocated. To achieve the ring effect, the remainders of all indices are used. Let’s assume there is a single producer. There will be a single index within the ring buffer designating the lastly written element. Once the producer creates/produces an input entry, the corresponding buffer entry will be updated and the counter incremented. That update should be “in-place” to avoid creating garbage. Each consumer maintains its own index designating the last read item. It waits until that index precedes the index of the producer and then can consume all newly produced elements. Waiting can be done in multiple ways – e.g. periodically polling. When multiple producers are involved, LMAX Disruptor can use CAS locking to determine the value of the producer index for each of them.
Using this approach we can avoid locking in most circumstances and we only use a preallocated fixed size data structure. However, if the producer significantly outpaces the consumers the buffer won’t be enough. Hence, it’s a good idea to preallocate huge buffers of thousands or even millions of elements. This will allow the consumers to catch up with a producer which suddently spikes in demand. If the consumers can’t catch up given such a huge buffer, then such computation would not be viable with any other queuing model as well – the only solution would be to improve the throughput of the consumers.
Apart from simple producer-consumer systems, the LMAX Disruptor can also increase the performance of pipeline or workflow systems. As one node is continuously producing/streaming data, the dependent nodes can consume it in real time with minimal latency.
Summary and Comparison
Green threads are emulated in user space. They are mostly used in environments where threads can not be mapped to native OS threads. Not used too much these days. Protothreads are stackless ligthweigth threads implemented in C. Won’t see them too much, unless you’re programming embedded low memory devices.
Fibers and Coroutines model the same concept. They are not truly parallel. However, they can make your life easier when dealing with asynchronous I/O. You can yield the fiber/coroutime after starting the I/O operation, and then resume it afterwards to update the user interface for example. This is much more efficient and elegant than using a background thread.
The Goroutines were defined in the Go programming language. Each Goroutine is a function which runs asynchronously. The runtime environment maps the goroutines to a pool of native OS threads in a way which minimises thread blocking and context switching.
The Actor model allows you to design a program in terms of entities/actors exchanging asynchronous messages. It is inherently decentralised, without locks, and an actor-based program can easily scale to multiple cores or machines. The most popular JVM actor system Akka maps actors to a pool of underlying threads, similarly to goroutines.
The LMAX Disruptor approach embraces threads, rather than trying to avoid them. It reduces the locking and communication overhead of message queues in a producer-consumer relationship.
Updated: with comments from Paul Bone