
Table of Contents
- Introduction
- Week 1: Parallel Programming
- Week 2: Basic Task Parallel Algorithms
- Week 3: Data Parallelism
- Week 4: Data Structures for Parallel Computing
Introduction
EPFL has released a new course on Parallel Programming, which is a part of the Functional Programming in Scala Specialisation. This post summarises the course and can be used as a quick ref-card on the topic.
Week 1: Parallel Programming
Parallel Programming Introduction
Parallel computing is concerned with the simultaneous execution of multiple computations. Its goal is faster execution than traditional synchronous/serial programs. It is enabled by parallel hardware.
Parallel computing is related to the concept of Concurrent computing. In a previous post, I overviewed the differences between the two concepts. In essence, concurrency is about composing independent computations to work together, while parallelism is about actually executing them simultaneously on suitable hardware. Concurrency is about the application design and structure, while parallelism is about the actual execution. Concurrency is about modularity and separation of concerns, while parallelism is about efficiency and execution speed-up.
At the most basic level, there are three types of parallelism:
- Bit level parallelism - by increasing the CPU word size (e.g. from 32bit to 64bit), the processor can act on bigger chunks of data with fewer operations. For example, two 64 bit integers could be added with a single instruction on 64bit processor. A 32bit machine would need multiple instructions.
- Instruction level parallelism - some chips can run multiple instructions simultaneously - e.g. processor pipelines.
- Task level parallelism - running separate instruction streams/series simultaneously.
We’ll focus on Task level parallelism, because it is on the “software level”.
Parallel hardware can be:
- Multi-core processors - multiple processing units (cores) on the same chip. They can potentially share caches.
- Symmetric multiprocessors (SMP) - multiple independent and identical processors. They can’t share caches, but use the same bus.
- General purpose graphics processing unit (GPGPU) - co-processors used together with CPUs. A GPGPU can have thousands of cores executing the same instruction at the same time, which is suitable for some applications.
- Field-programmable gate arrays (FPGA) - a programmable integrated circuit.
- Computer clusters - a set of computers connected in a high speed network. They work together and appear to the user as a single computer.
We’ll focus on multi-core and symmetric multiprocessor systems.
Parallelism on the JVM
On the operating system (OS) level, a process is an instance of a program being executed and has its own address space. Processes can not access each others’ address spaces and are isolated. Inter-process communication techniques like sockets and pipelines can be used to communicate between processes.
OS processes can be expensive to create, as each one has its own address space, program code, open file handles etc. Furthermore, the inter-process communication can be inefficient and cumbersome to program.
Enter threads (a.k.a. lightweight processes). A thread is a separate line of execution (a sequence of instructions) within a process. A process can have multiple threads, all of which share its address space, file handles etc. Starting a thread is cheaper, as fewer resources need to be allocated. The threads within a process are concurrent and can execute in parallel. Each thread maintains its own programming stack. Alike processes, the OS scheduler preemptively schedules all threads.
Scala uses the JVM classes for threads, and hence creating and starting a thread is very similar to Java. One approach to creating a thread is to extend from the Thread class:
1
2
3
4
5
6
7
// Subclassing class Thread
class CustomThreadClass extends Thread {
// Override the run method - its code will
// be run in a separate thread
override def run = println("From CustomThreadClass")
}
Then we can start a thread from that class and wait for its completion (join):
1
2
3
4
5
6
7
val thread = new CustomThreadClass()
// Start the thread
thread.start()
// Block the current thread until it's finished
thread.join()
It is often important to ensure that a piece of code is atomic - i.e. it can not be
executed simultaneously from multiple threads. To achieve this, the JVM provides
synchronized code blocks. Each such block is associated with a “monitor object”,
and only one thread can execute the block associated with it. Here’s an example:
1
2
3
4
5
6
7
8
9
10
11
12
// Thread class - takes the monitor as a constructor arg
class Atom(name : String, monitor: AnyRef) extends Thread {
override def run = {
// Synch by the monitor given in the constructor
monitor.synchronized {
// This code can not run smultaneously for a given monitor
println(s"Atomic Operation Part 1 in $name")
println(s"Atomic Operation Part 2 in $name")
println(s"Atomic Operation Part 3 in $name")
}
}
}
Then we can run the following experiment:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// We'll use this reference to implement atomicity
val monitor = ""
// Pass the same monitor to the threads
val thread1 = new Atom("Atom 1", monitor)
val thread2 = new Atom("Atom 2", monitor)
// Start the threads. Their executions will not overlap.
thread1.start()
thread2.start()
// Block the current thread until they're finished
thread1.join()
thread2.join()
This overview of JVM threads only scratches the surface. For more details you can refer to the official tutorial, which covers more advanced topics on threads and processes.
Complexity of Parallel Algorithms
For serial algorithms, we often use the big-O notation to evaluate their computational complexity. Ideally, we would like to do the same with parallel algorithms. However, in the parallel case we’ve got an additional parameter - the number of processing units.
Let us denote by \( W(e) \) the number of steps needed by the computation/algorithm \( e \). We’ll call \( W(e) \) the work required for \( e \), and it’s a measure of the time it would take if executed serially. If \( e \) is run in parallel, then \( W(e) \) is an upper bound of the execution time.
Now we can introduce a lower bound as well. With \( D(e) \) we denote the execution time of \( e \) if given infinite number of processing units. We call \( D(e) \) the depth of \( e \).
Assuming our hardware has capacity to run \( P \) number of threads simultaneously, we can approximate the execution time as:
\[ D(e) + \frac{W(e)}{P} \]
The rationale is that when \( P \) grows, this expression is asymptotically equivalent to the depth \( D(e) \). If \( P \) is a relatively small number, then the expression has the same complexity as the work \( W(e) \).
But how can we estimate the effect of adding more resources (i.e. increasing \( P \)) to a computation? Amdahl’s law comes to the rescue. Let’s assume that the computation \( e \) has 2 parts:
- Part 1 which is not parallelisable;
- Part 2 which is absolutely paralelisable - i.e. can benefit from as many independent threads that the hardware can provide.
Let’s denote by \( f\) the fraction of the serial execution time (i.e. \( W(e)) \)) that is dedicated to running Part 1. Then we can approximate the execution time as:
\[ f \cdot W(e) + \frac{(1-f) \cdot W(e)}{P} \]
This means that adding more resources will only speed-up the parallelisable part of the computation. From this formula, we can deduct the original statement of the law that the speed-up of adding more resources to a computation \( e \) is:
\[ \frac{1}{ f + \frac{1-f}{P} } \]
Benchmarking
The asymptotic complexity of a parallel algorithm gives us a rough estimate of the actual running time. In practice, there are many other factors that affect the actual execution time. The CPU speed, the number of processing units, the memory access speed, and the cache size and policies are just a few of hardware factors affecting application performance. Furthermore, the operating system (OS) scheduling of threads and processes and the execution environment behaviour in terms of garbage collection (GC) and just-in-time (JIT) compilation can have dramatic effects. Hence, benchmarking is an invaluable tool for assessing performance.
Running the same benchmark execution multiple times can give us very different results. Hence, we should take aggregate descriptive statistics of repeated runs (e.g. the mean or the interquartile range) as evidences of the actual performance. Furthermore, it makes sense to eliminate outliers, because they are most likely a result of extreme events (e.g. garbage collection or swapping).
Another trick is to start measuring the application performance after it has been running for some time. This is called warm-up period. The idea is that during the warm-up period the JIT compilation whould be complete and the caches should be populated with commonly accessed data. Therefore, measuring the application performance afterwards should give more representative results.
A popular library for benchmarking is ScalaMeter. Here’s how to benchmark a piece of code:
1
2
3
4
5
6
7
8
9
10
// Import all from the ScalaMeter library
import org.scalameter._
// Runs a block and returns how long it took in millisecons
val time = measure {
// The code we want to benchmark
(0 until 100000000).map(math.pow(_, 5)).sum
}
println(s"The operation took: $time ms")
Now lets see how we can add warm-up to our measurement:
1
2
3
4
5
// Use the default ScalaMeter warmer
val time = withWarmer(new Warmer.Default).measure {
// The code we want to benchmark
(0 until 1000000).map(math.pow(_, 5)).sum
}
We can also configure the warmer’s parameters (e.g. min and max number of runs):
1
2
3
4
5
6
// Custom config of the warmer
val time = config(Key.exec.minWarmupRuns -> 30,
Key.exec.maxWarmupRuns -> 60).withWarmer(new Warmer.Default).measure {
// The code we want to benchmark
(0 until 1000000).map(math.pow(_, 5)).sum
}
ScalaMeter has many more functionalities. It can measure memory consumption, ignore Garbage collection periods, count method invocations and so on. Consult the documentation to learn more :).
Week 2: Basic Task Parallel Algorithms
Parallel Sorting (MergeSort)
Merge sort is an algorithm that lends itself to parallelisation. At each step, it divides the array in two, sorts the two parts recursively, and then merges them. These two recursive calls could be run in parallel.
We can limit the level of parallelisation by the depth of the recursion, because at every stage we’ll have \( 2^{depth -1 } \) execution threads. When the depth becomes bigger than a certain threshold, we’ll just use a serial algorithm (e.g. quicksort). By setting the threshold appropriately, we can control how many simultaneous threads of execution are running. It sensible to avoid running more independent non-blocking threads than the number of computing nodes or cores to avoid excessive context switching and resource saturation.Here is the pseudocode of the solution:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
def sort(arr: Array[Int], from: Int, to: Int, depth: Int, maxDepth: Int) = {
if(depth >= maxDepth) {
// Sequential sorting
quicksort(arr, from, to)
} else {
val m = (from + to) / 2
// Run them in separate threads join with them
parallel(sort(m, to, depth+1),
sort(from, m, depth+1))
// Sequentially merges the two subarrays
merge(arr, from, to, m)
}
}
This snippet shows the gist of the algorithm, and ignores some trivia around using an auxiliary array for the merging. However, that process could be parallelised as well. For example, we can copy values from one array to another in parallel using the same idea:
1
2
3
4
5
6
7
8
9
10
11
12
def copy(src: Array[Int], dst: Array[Int] from: Int, to: Int, depth: Int, maxDepth: Int) = {
if(depth >= maxDepth) {
// Sequential copy (e.g. Array.copy)
sequential_copy(src, dst, from, to)
} else {
val m = (from + to) / 2
// Run them in separate threads and join with them
parallel(copy(m, to, depth+1),
copy(from, m, depth+1))
}
}
Parallel Mapping and Reduction
A great deal of programming is about working with collections - e.g. filtering, mapping, reducing lists/sets/dictionaries. If we could parallelise these operations in a way which is transparent to the end programmer, then seemingly serial programs could reap the benefits of parallel hardware behind the scenes.
As we saw in the previous section, applying parallel algorithms
often requires access to arbitrary values from the collection -
e.g. the middle element. Scala’s List doesn’t lend itself to
parallelisation as it is just a pair of a head and a tail.
We’ll focus on arrays and trees instead.
Mapping an array in parallel is quite trivial. We just need to divide it in two, and run parallel recursive calls for the two parts. Once the array length reaches a certain threshold, we can use serial mapping.
Similarly, trees can be mapped in parallel by traversing them and running parallel recursive calls for each child. Once we’ve reached a certain threshold depth in the tree, we can start running serial mapping.
Folding/reducing a data structure is more difficult than mapping because,
in the general case, computations depend on each other.
Let’s assume we have an array val a = Array(3,2,1) and we invoke
a.reduceLeft(_ - _). This can not be run in parallel, as the
evaluation of (3-2)-1 depends on the evaluation of 3-2.
However, if the reducing function is associative we can run
the computations in parallel. A function f is associative iff
f(a,f(b,c)) = f(f(a,b),c) for every a, b, and c.
For example def f(a:Int, b: Int) = a+b is associative, because
(a+b)+c = a+(b+c). However, def g(a:Int, b: Int) = a-b
is not.
Associativity allows us to run things in parallel, because
we can “put the brackets” any way we want. More formally, if
f is associative then the following expressions are equivalent:
1
2
3
4
5
6
7
8
// Reduce/fold definition
f(a1, f(a2, ... f(an-1, an) ))
// Equivalent if f is associative
val m = n / 2
val firstHalf = f(a1, ... f(am-1, am))
val secondHalf = f(a1, ... f(am+1, an))
f(firstHalf, secondHalf)
In other words, if f is associative we can split the array in parts,
compute the reduction of the parts, and then combine/reduce these
values with f. These independent sub-reductions can be run in
parallel analogously to what we did for map.
Associativity
As we just saw, associativity allows us to reorder a sequence of
computations and run them in parallel. Another important
property of two-arguement functions is commutativity. A function
f is commutative if f(a,b)=f(b,a) for every a and b.
Here are some examples of functions which are both associative and commutative:
- Sum of integers, because
(a+b)+c = a+(b+c)anda+b = b+a; - Multiplication of integers (analogous to summation);
- Union of sets, because \( (A \cup B) \cup C \) = \( A \cup (B \cup C) \) and \( A \cup B \) = \( B \cup A \);
- Intersection of sets (analogous to union);
- Boolean conjunction:
(a && b) && c = a && (b && c)anda && b = b && a; - Boolean disjunction (analogous to conjunction);
Examples of associative but not commutative:
- List concatenation:
(a++b)++c = a++(b++c)buta++b = b++ais not always true; - Matrix multiplication: \( (A \times B) \times C = A \times (B \times C) \) but \( A \times B \) = \( B \times A \) is not always true.
Examples of commutative but not associative:
- Sum of floats:
a+b = b+abut(a+b)+c = a+(b+c)may not be true due to the different accumulated roundings. - Multiplication of floats (analogous to summation);
Week 3: Data Parallelism
There are two main “styles” of parallelism - task and data parallelism. In the task based approach, we distribute the execution of different computations across multiple processing units. Data parallelism is when we run the same computation with different parameters/data on multiple units.
The efficiency of the task parallel approach grows with the number of independent tasks you can break the problem in. On the contrary, data paralelism’s efficiency grows with the quantity of the data.
An example of task parallelism is a client-server system, which has
separate threads for serving requests, making requests, etc.
An example of data parallelism is a parallel for loop,
where an array is subdivided into parts and the body of the
loop is run in parallel over all parts.
Data Parallelism in Scala Collections
In Scala, the standard library consists of standard/serial
collections and parallel collections. For most collections,
there is a parallel alternative prefixed with “Par” -
e.g. Set and ParSet. To allow the development of code
which works with both serial and parallel collections, there
are generic alternatives of all collections which are supertypes
of both the serial and parallel versions:
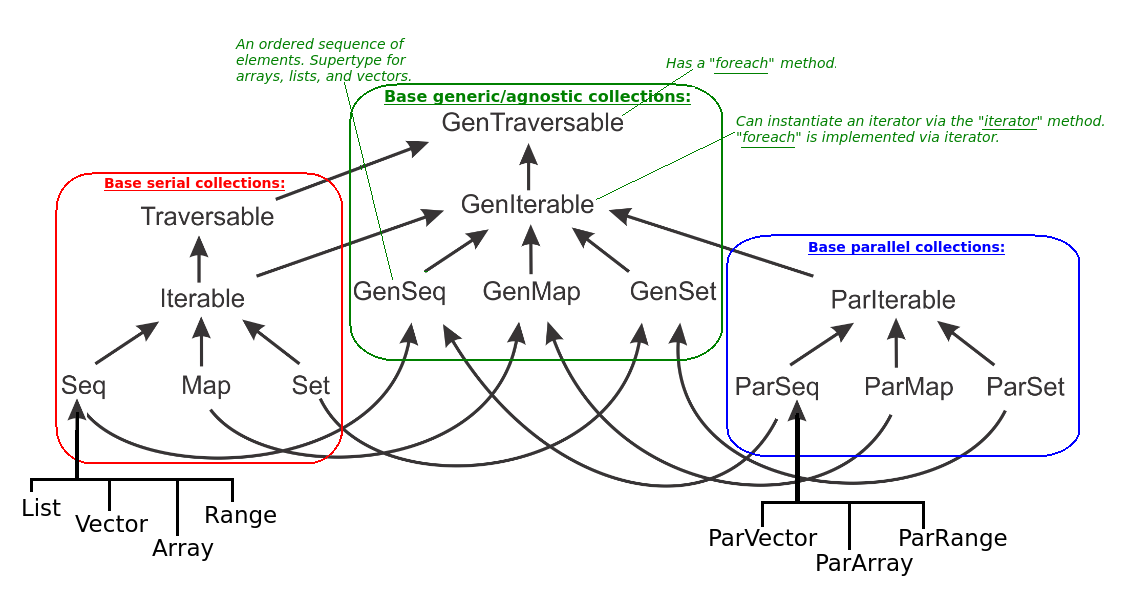
Note that there’s no collection ParList. As
discussed List, which is pair of a head element and tail,
is not suitable for most parallel operations.
Every collection can be converted to its parallel alternative via
the par method. For example:
1
2
3
4
5
6
7
Set(1,2,3).par // Returns a ParSet instance
Array(1,2,3).par // Returns a ParArray instance
(1 to 5).par // Returns a ParRange instance
List(1,2,3).par // Returns a ParVector instance
Splitters and Combiners
Scala standard collections provide the Iterator interface/trait, which is
typical for imperative languages. A simplified version is:
1
2
3
4
trait Iterator[A] {
def next(): A
def hasNext: Boolean
}
We can define the sequential fold/reduce operations for every collection
that we can convert to an iterator. However, for the parallel reduction
we’ll need a way to split the collection in parts which we can process
in parallel. Hence, some collections provide Splitters. The
simplified trait can be defined as:
1
2
3
4
trait Splitter[A] extends Iterator[A] {
def split: Seq[Splitter[A]]
def remaining: Int
}
The split method returns disjoint sub-collections of the present
collection. It should be an efficient method with not more than
\( O(log(n)) \) complexity. The remaining method returns an
estimation of the number of elements in the splitter.
Usually, algorithm compare the remaining value to a threshold
to determine whether to continue splitting and run the
sub-collections in parallel rather than just run sequentially.
Scala standard collections also provide the Builder interface/trait,
whose simplified version is:
1
2
3
4
trait Builder[A,Repr] {
def +=(elem: A): Builder[A,Repr]
def result: Repr
}
Where Repr is type of a collection - e.g. List, Vector, etc.
The += operation adds to the builder. The result method returns
the created resulting collection of type Repr.
Having Builder implementations for every collection allows us
to implement the serial version of filter in a collection
agnostic way:
1
2
3
4
5
6
7
def filter(p: T => Boolean): Repr = {
val b = newBuilder
for (x <- this)
if(p(x))
b +=x
b.result
}
In order to implement parallel filter/reduce, we can use
appropriate Splitter instances to divide the collection
into subparts that can be processed in parallel. Then, we need
a way to combine the results of the independent parallel
computations in parallel. For this, there’s the
Combiner interface:
1
2
3
trait Combiner[A, Repr] extends Builder[A, Repr] {
def combine(that: Combiner[A, Repr]) :Combiner[A, Repr]
}
The combine function aggregates the two combiners.
It should be faster than
\( O(log(n)) \).
The parallel collections in Scala all have splitters and combiners through which the parallel algorithms are implemented in an uniform way.
Week 4: Data Structures for Parallel Computing
We saw that the Combiner interface is a useful tool to
implementing parallel data structures in a unified way.
But how should we implement efficient combiners for the
most commonly used collections?
A combiner for sequences would implement the concatenation operation, while a combiner for sets/maps would implement union. However, arrays can’t be concatenated efficiently and most sets/maps take linear time for union.
Two-Phase Construction
To overcome these problems, most combiners use intermediate
data structures. In other words, such combiners
work in two phases. Firstly, they efficiently aggregate/combine
elements (i.e. using += and combine) into the intermediate
data structure. Secondly, they efficiently convert from this
intermediate representation to target one (i.e. the Repr type
parameter).
For example, the combiner for arrays
is implemented with an array list (i.e.
ArrayBuffer)
of array lists of the actual elements - i.e. ArrayBuffer[ArrayBuffer[T]].
When a new element is added (with +=) to the
combiner, it appends it to the last list, which has
\( O(1) \) complexity. When two array combiners are
concatenated (with combine) their lists of lists are concatenated.
This operation is linear with respect to the “outer lists”, but is on
average logarithmic with respect to the total number of elements
in the two collections. Finally, the underlying array lists
can be combined into an array in linear time. This could be further
improved by running the concatenation in parallel on multiple processors.
Similarly, we can implement efficient combiners for hash sets and maps. We can partition the hash codes into buckets corresponding to integer ranges. This allows for the element addition and union can be implemented efficiently. Converting back to original collection takes linear time and is parallelisable.
Conc-Trees
We saw that we can implement efficient combiners for arrays, hash sets, and hash maps. But how about trees? If a tree is no balanced then running parallel operations on it can be challenging.
Conc-Trees are binary tree data structures with efficient addition and union operations that maintain its balanced form. It can be used to implement efficient combiners for arrays.