
Introduction
In a previous post I introduced the CloudSimEx project featuring a set of CloudSim extensions and I discussed how to set it up in Eclipse and work with it. In this post I’ll focus on how CloudSimEx enables disk operations modelling.
CloudSim and most other distributed system performance simulators only represent CPU instructions. In other words, each job/cloudlet is defined only by the number of CPU operations it requires. However, many applications are disk I/O bound, not CPU bound and they work intensively with database services or files on the local storage. In a previous publication we’ve explained at a high level how disk operations can be simulated. In this post I’ll demonstrate how this works in practice with CloudSimEx.
Prerequisites
I assume you’ve already worked through Part 1 of this series. If not, now is a good time to check it out - CloudSim and CloudSimEx [Part 1].
Model
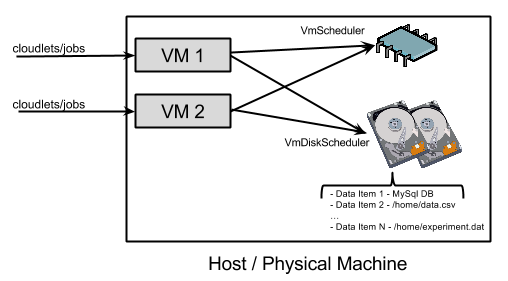
In the core CloudSim every Host has a CPU with one or many cores, which are represented by the Pe class. The CPU instructions are distributed to a host’s VMs by a VmScheduler. The most widely used scheduler is VmSchedulerTimeShared, which allocates one or more cores (i.e. Pe) to a VM, and allows sharing of PEs by multiple VMs. Each Vm has a predefined CPU requirements that the scheduler tries to honour when distributing the host’s CPU resources.
CPU cores and disks are similar concepts to model, since they both have some predefined capacity/throughput of
operations they can perform during a given time interval (either CPU or disk I/O operations) which needs to be
shared among the virtual machines. Thus, in CloudSimEx we represent a disk with the class
HddPe,
which extends Pe. The difference between a CPU core (Pe) and a disk (HddPe) is that
a disk has data items stored on it. A data items is a block of persistent storage used by an application - e.g. a file or a database shard.
We also introduce new types of hosts
(HddHost)
and virtual machines
(HddVm)
that accommodate disks. A HddHost can have one or more disks (i.e. HddPe). A HddVm has
an additional property defining how many disk operations it requires from the hosts, similarly to the way
each Vm has a number of CPU operations per second as a requirement.
Also, each HddVm has a list of attached disks. Thus, a virtual machine
can have access to all or a subset of the disks of its host. Each HddHost has a
VmDiskScheduler
which allocates the available throughput of its disks to the hosted virtual machines,
similarly to the way a VmScheduler allocates CPU operations to VMs.
In fact, under the hood a VmDiskScheduler uses a dedicated VmScheduler to manage each disk.
The following diagram depicts the above concepts.
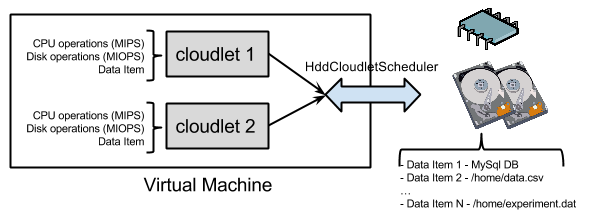
Once disk and CPU operations are distributed among the virtual machines, they in turn need to distribute
them to their cloudlets/jobs. Thus, CloudSimEx introduces a new type of cloudlet -
HddCloudlet.
In addition to the number of CPU instructions (mips), it also has a number of disk I/O operations
(miops) and a data item. In CloudSim, a standard cloudlet is complete/finished only if mips
CPU instructions have been assigned to it by the virtual machine. In CloudSimEx, a HddCloudlet is
complete only if both mips CPU and miops disk operations have been provided by the VM.
In other words, a HddCloudlet is finished only when it has executed all of its both CPU and disk instructions.
To distribute disk and CPU operations, each HddVm uses a dedicated scheduler -
HddCloudletSchedulerTimeShared.
It distributes the CPU and disk operations in a time-shared manner (i.e. similar to CloudletSchedulerTimeShared).
However, when assigning disk operations to a cloudlet, it only uses instructions from the disk which hosts its data item.
If no such disk is accessible from the VM - the cloudlet fails. In other words if a cloudlet has a given data item (e.g. a file)
the HddCloudletSchedulerTimeShared will only allocate operations from the disk which hosts it, if it is
available to the VM. Otherwise, the cloudlet will fail.
The following diagram depicts the above concepts:
Some Code Please
The samples below are extracted from
CloudSimDisksExample.
The code excerpts below assume you have defined all capital letter constants like HOST_MIPS, HOST_MIOPS etc. You can look at
CloudSimDisksExample
to see how these can be defined.
Lets start by creating a few data items, which later on we’ll position on two disks:
1
2
3
4
5
6
7
// These two items will reside on the first disk
DataItem dataItem_1_1 = new DataItem(DATA_ITEM_SIZE);
DataItem dataItem_1_2 = new DataItem(DATA_ITEM_SIZE);
// These two items will reside on the second disk
DataItem dataItem_2_1 = new DataItem(DATA_ITEM_SIZE);
DataItem dataItem_2_2 = new DataItem(DATA_ITEM_SIZE);
Next we can create lists of CPUs and disks - i.e. Pe and HddPe. Disks are associated with data items in the constructor:
1
2
3
4
5
List <pe>peList = Arrays.asList(new Pe(Id.pollId(Pe.class), new PeProvisionerSimple(HOST_MIPS)));
HddPe disk1 = new HddPe(new PeProvisionerSimple(HOST_MIOPS), dataItem_1_1, dataItem_1_2);
HddPe disk2 = new HddPe(new PeProvisionerSimple(HOST_MIOPS), dataItem_2_1, dataItem_2_2);
List <hddpe>hddList = Arrays.asList(disk1, disk2);
Next we can create a host with these CPUs and disks:
1
2
3
4
5
6
7
HddHost host = new HddHost(new RamProvisionerSimple(HOST_RAM),
new BwProvisionerSimple(HOST_BW),
HOST_STORAGE,
peList,
hddList,
new VmSchedulerTimeShared(peList),
new VmDiskScheduler(hddList));
After that you can create a data centre with this host and a broker.
This is standard CloudSim stuff. The only difference is that you need to use HddDataCenter instead of just DataCenter:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// Build the data centre and a broker
List hostList = Arrays.asList(host);
DatacenterCharacteristics characteristics = new DatacenterCharacteristics(ARCH,
OS,
VMM,
hostList,
TIME_ZONE,
COST,
COST_PER_MEM,
COST_PER_STORAGE,
COST_PER_BW);
List <storage>storageList = new ArrayList<>();
HddDataCenter datacenter = new HddDataCenter("DC",
characteristics,
new VmAllocationPolicySimple(hostList),
storageList, 0);
DatacenterBroker broker = new DatacenterBroker("Broker");
Now we’ll create a VM which has access to only one of the disks and submit to the broker:
1
2
3
4
5
6
7
8
9
10
11
12
13
Vm vm1 = new HddVm("TestVM",
broker.getId(),
VM_MIPS,
HOST_MIOPS,
1,
VM_RAM,
VM_BW,
VM_SIZE,
VMM,
new HddCloudletSchedulerTimeShared(),
new Integer[] { disk1.getId() });
broker.submitVmList(Arrays.asList(vm1));
Now finally we can run some cloudlets:
1
2
3
4
5
6
7
8
9
10
11
12
13
// Create cloudlets accessing data items on disk 1 and disk 2 respectively
HddCloudlet cloudlet1_1 = new HddCloudlet(VM_MIPS * 1, HOST_MIOPS * 2, 5, broker.getId(), false, dataItem_1_1);
HddCloudlet cloudlet2_1 = new HddCloudlet(VM_MIPS * 1, HOST_MIOPS * 2, 5, broker.getId(), false, dataItem_2_2);
// Associate them with the VM
// cloudlet1_1 will execute, as vm1 has access to disk1 and dataItem_1_1
cloudlet1_1.setVmId(vm1.getId());
// cloudlet2_2 will fail, as vm1 has no access to disk2 and dataItem_2_2
cloudlet2_2.setVmId(vm1.getId());
// Submit...
broker.submitCloudletList(Arrays.asList(cloudlet1_1, cloudlet2_2));
Relation to CloudSim storage
The core CloudSim code already defines some storage related attributes. They are not related to the above functionalities!
For example each data centre can have a List<Storage> property.
Storages like SAN storage are supported in CloudSim.
However, you can not use these CloudSim entities to represent contention
when accessing persistent data either at the VM or cloudlet/job level.
Extensibility
CloudSimEx comes with default implementations of the scheduling policies.
However, you can implement your own VmDiskScheduler and HddCloudletScheduler extensions,
which distribute CPU and disk operations with respect to your application’s requirements.